Replicating the Scaling Laws!
Goal
"Scaling laws, scaling laws, scaling laws." It's all i ever hear about nowadays in the online AI space, but what are they? And can i replicate them? In this blog, I get my hands dirty to try to deeply understand the scaling laws!
What are the scaling laws
Put simply
Imagine you're a cook, and you're given the recipe for pizza, which is sauce, dough, and cheese. The scaling laws say that the more cheese you have (as long as there's enough dough and sauce), the more pizza you can make. Or, the more dough you have, (as long as there's enough cheese and sauce) the more pizza you can make!
For autoregressive models, the recipe is model size, dataset size, and compute. The scaling laws say that as you add more compute or use a bigger model or dataset, as long as you're not constrained by the others, the more intelligence you can have!
Put exactly, the relationship is a powerlaw like so
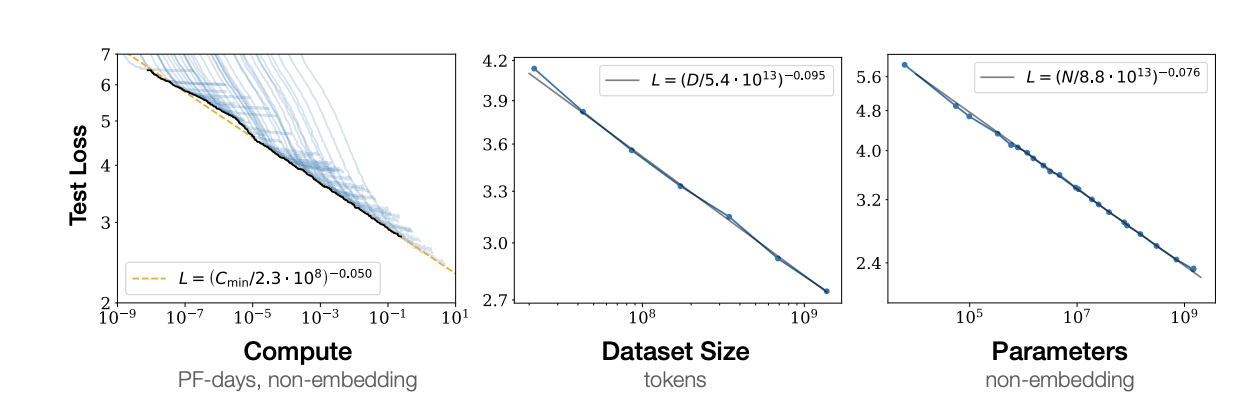
Where roughly for every
- 10x more compute gives only about an 11% reduction in loss.
- 10x larger dataset, and you get a 20% reduction in loss
- 10x larger model size, 16% reduction in loss
The key understanding of these laws is that other factors (like network width or depth) don't seem to have as big of an impact as compute, dataset size, and model size
So, this explains why Sam altman and Dario amodei are raising billions and billions of dollars in compute. With somewhat diminishing returns
If all they did was increase their compute budget from 100 billion to 200 billion, one would think that the model would be 2x better, but based on the scaling laws we'd actually only see a 3.4% decrease in model loss!
This explains why models like GPT 4.5, which were trained with much more compute and a much larger model size than it's predecessor GPT 4o, showed modest gains for a significantly higher price!
Anyway, let's get to the experiemnts
Setup
For technicality, in these experiments, I used a small decoder-only autoregressive language model in PyTorch, with a single attention head. I trained on the WikiText-2, WikiText-103, and OpenWebText subset datasets. And, used an AdamW optimizer.
We denote
- N as parameter count
- D as dataset size
- And C as training compute
Experiments
click here to see my colab notebook
1. Scaling model size
For our first experiment, we wanted to see if varying model size while fixing compute and dataset size would follow the scaling laws, at first we tried training with differing model sizes on the smaller WikiText-2 dataset,
Running the models, we get these results.
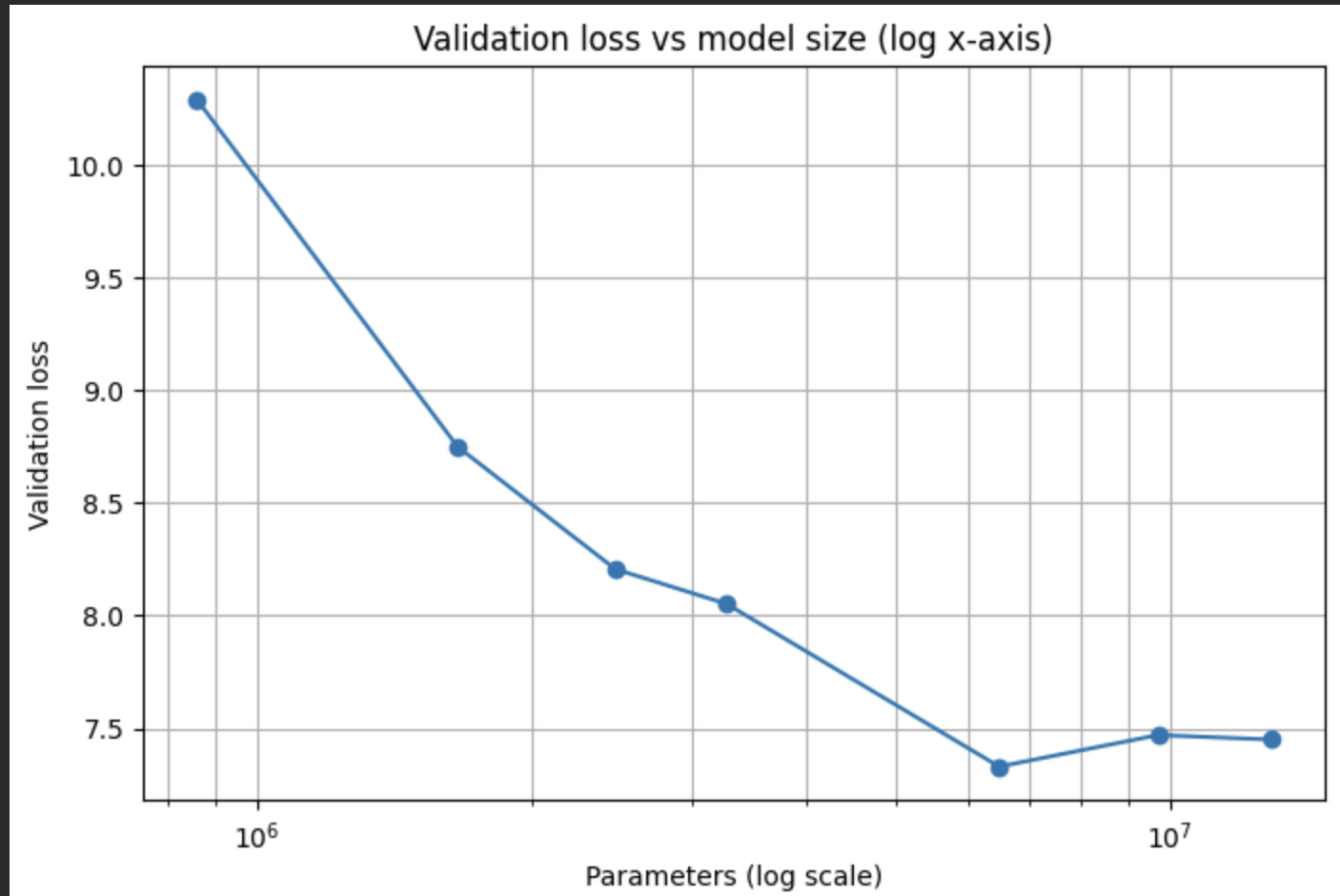
This is nice, but
We noticed that towards the higher end of model size, the loss drop was plateauing. I hypothesized that this had to do with WikiText-2 being somewhat small, so we tried WikiText-2's bigger brother, WikiText-103, which is about 100x bigger than WikiText-2.
Here are the results
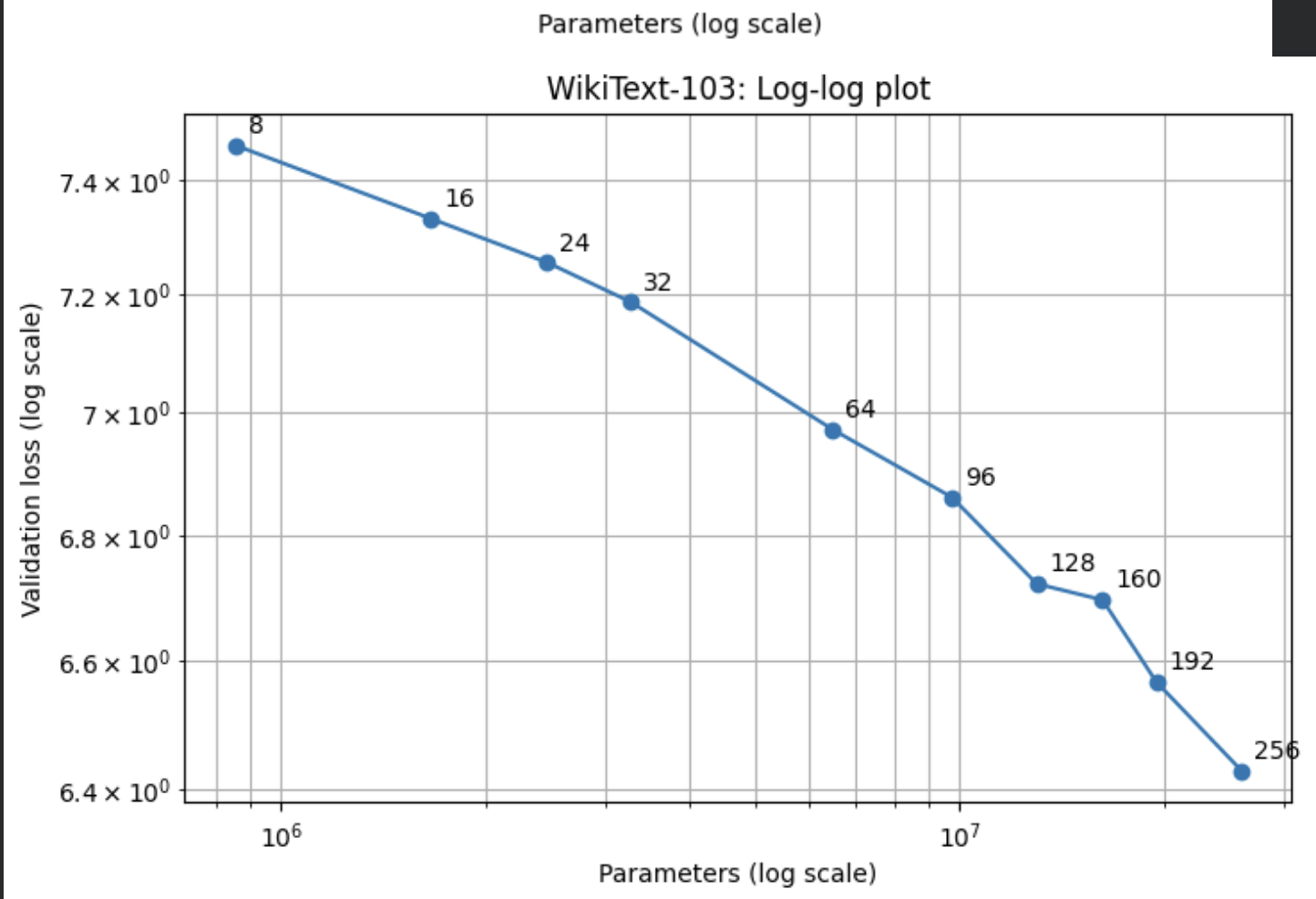
Not bad! Looks a lot like the Kaplan et. al graph.
After fitting an equation to the line of best fit
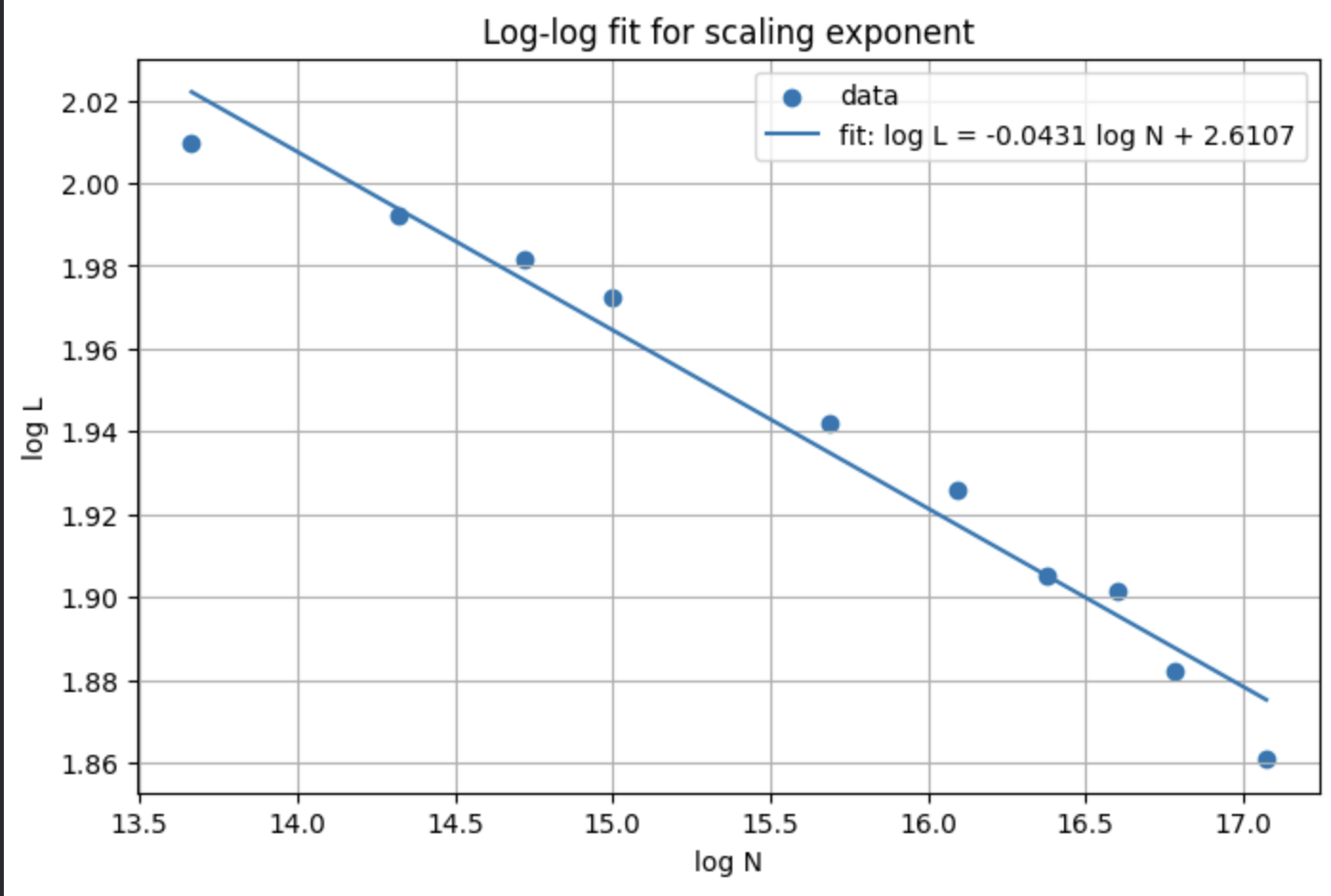
It's obvious that indeed, there is a power law relationship for model size
2. Scaling dataset size
For our second experiment, we decided to vary the dataset size and fix compute and model size.
After running the experiment, we got these results
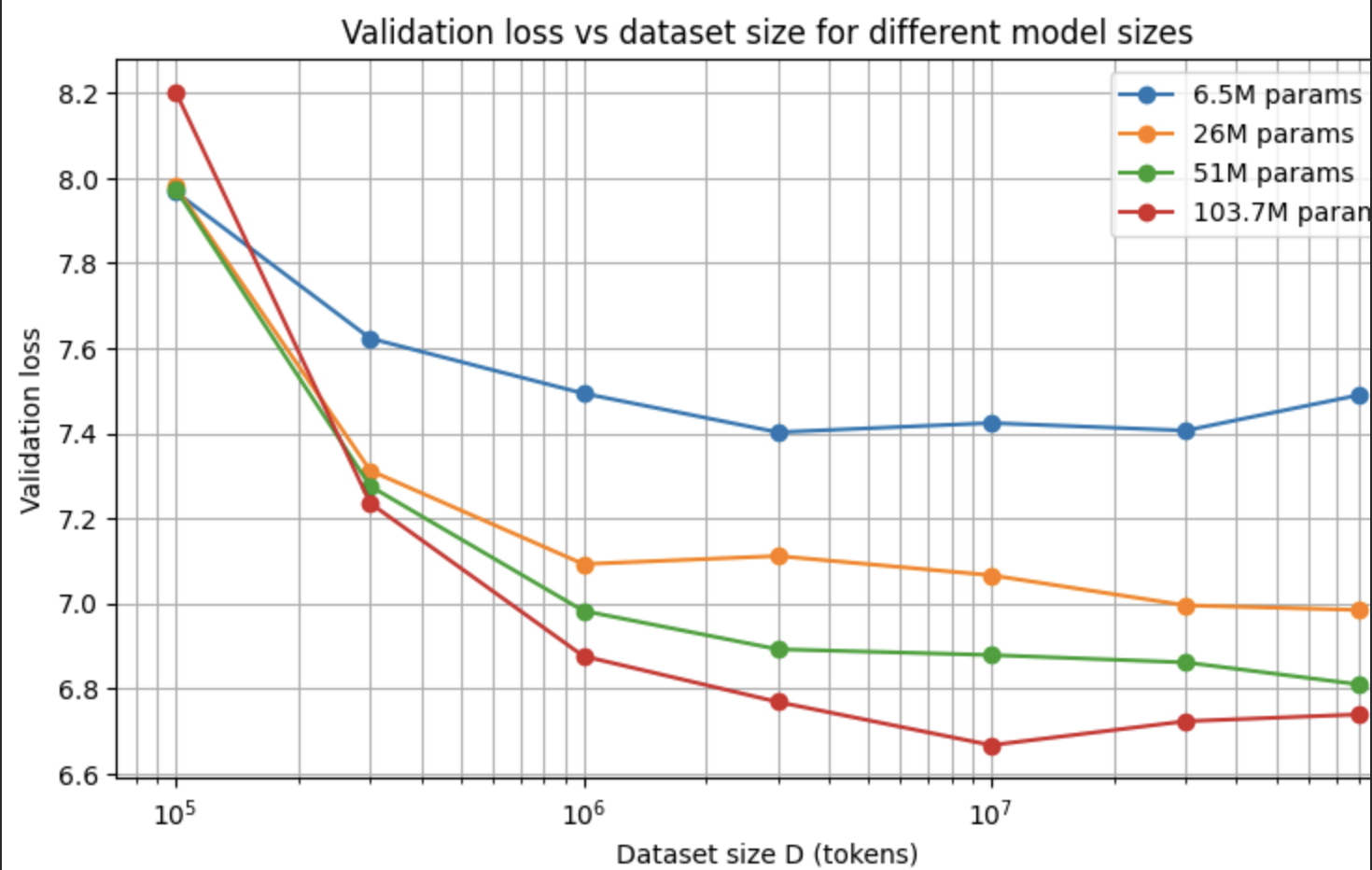
I noticed that the increase in dataset size seemed to drop validation loss at smaller dataset sizes, but as we got more and more data, the loss drop seemed to plateau.
The paper talks about how these laws can only apply as long as they're not bottlenecked by the other factors, which would be computer and model size here. So, i increased model size, as you can see in the graph above. This gave better results, but there was still a plateau, so I knew the other bottleneck had to be compute. This led to my last experiment
3. Scaling compute to remove the bottleneck
For our third experiment, I hypothesized that the reason we were seeing these plateaus in model performance was because the models were being undertrained due to a lack of compute. To address this, we decided to scale up compute as we scaled up dataset size, so the model would have enough compute to actually take advantage of the larger datasets
The orange line shows the results! Much better
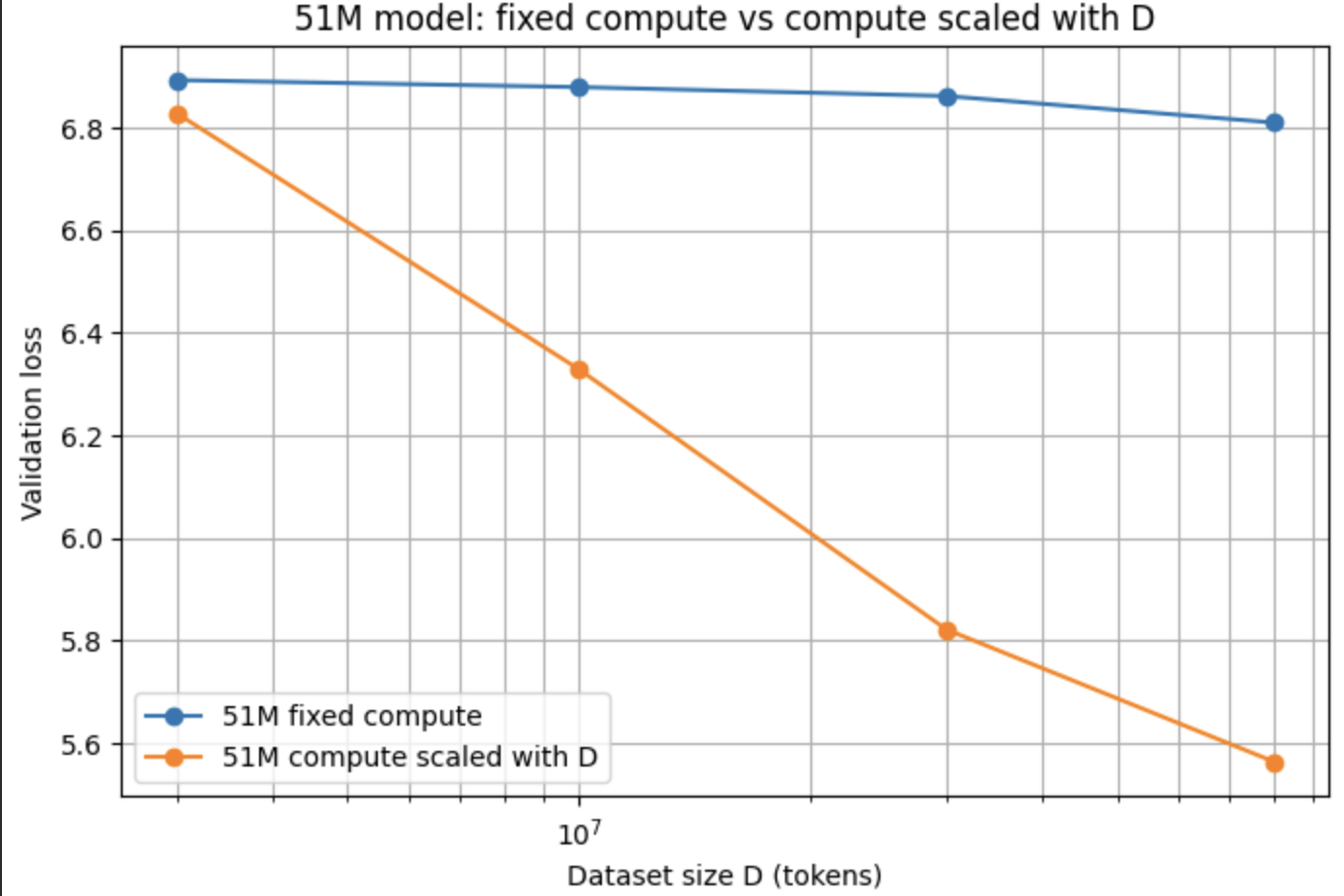
As dataset size and compute size scales, the loss also drops in a power law fashion. Nice.
Interpretation
Given these results, it looks like the scaling laws really do hold, at least for our small setup. As you increase model size, dataset size, and compute, the loss decreases in a power law fashion. But, the cool part is that the experiments also showed the bottlenecks the Kaplan et al. paper talks about. Small datasets caused early plateaus, bigger models made larger datasets useful for longer, and some of the plateaus disappeared once compute was scaled up. So the scaling laws are not just about “more is better,” but about which factor is currently limiting performance
Takeaways
The scaling laws still hold at models with trillions and trillions of tokens. The amount of compute, model size, and dataset size still primarily govern the quality of large models. But this also shows a limitation. As time goes on, multiplying the amount of compute you can allocate towards a model becomes harder and harder, and because it is a power law, the returns of scaling can diminish. With test time compute, labs were able to ride this scaling a little longer, but can they keep it up at this pace? Or will it even matter.
Anyway, I had a lot of fun learning about the scaling laws and running these experiments, thanks for reading! Have a great day.
Limitation
It is important to note that this is a toy model with one attention head and a small dataset, but it still shows that the power law scaling relationship is replicable.